ISWC 2019
A trip report

In the last week of October 2019 I attended the International Semantic Web Conference (ISWC) in Auckland, New Zealand. I had the honor to present my PhD plan at the ISWC Doctoral Consortium. In this blog post I talk a bit about the conference and focus on a few presentations I found particular interesting or relevant for my PhD regarding guidelines for the design and use of ontologies.
First things first: I will provide a bit of context and say what I liked/disliked.
The International Semantic Web Conference (ISWC) is THE conference of research regarding the Semantic Web also covering Linked Data, Knowledge Graphs and AI. This year it was held in Auckland New Zealand which on the one hand is an amazing venue, but on the other hand resulted in super long flights and visa issues for a lot of attendees.
What I liked the most The conference also had several sessions regarding ontologies and ontology design which is relevant for my PhD.
What I didn’t like I missed a few really good workshops because I had to attend the Doctoral Consortium a full day. Fully attending it is a good thing, just a pity it overlaps with other workshops.
OTTR tutorial
For the first workshop day I’ve chosen to attend the tutorial on scalable construction of sustainable knowledge bases which was all about the Reasonaable Ontology Templates (OTTR) framework. It was given by Martin G. Skjæveland, Leif Harald Karlsen and Daniel Lupp from the University of Oslo, and Melinda Hodkiewicz from the University of Western Australia.
In a nutshell OTTR is a language and a framework to describe knowledge on a conceptual level, whereas it abstracts from the actual knowledge representation in e.g. OWL. Thus ontology engineers can communicate with domain experts in their language and talk about for example a Person without needing to know which concrete axioms are used to represent a person in OWL. Templates contain parameters representing the variable part of a template which then gets extended to RDF together with its static part; working with templates feels like working with a constructor in languages such as Java.
I was particular interested in this tutorial as I see OTTR as the missing building block to generate different ontology representations based on the same conceptual model which is relevant for my PhD. The tutorial introduced the basics, we could get our hands dirty on some examples and then two real-life use cases were introduced.
Melinda Hodkiewicz stressed the need for ontologies in the Engineering sector, which she did as well in each session I have seen her during the main conference 😃. Which is nice, we need more enthusiastic people such as her to promote our work and highlight its concrete added value for businesses or the end user.
Besides the content I really liked the usage of https://menti.com to interactively get feedback from the audience such as demographics or incentives to join the tutorial. And the end of the tutorial the organizers went back to the initially asked questions and incentives of the audience and it was discussed whether each point was addressed. Thumbs up, please more of that in the future!
Doctoral Consortium
A lot of workshops took also place at the second day but I didn’t attend as I has the great pleasure of participating in the ISWC Doctoral Consortium all day where I could present the plan for my PhD.
The doctoral consortium started with a great keynote given by Valentina Tamma. She started by defining what a PhD means according to its definition, i.e. doctor of philosophiae in Greek “love of knowledge”, and continued with further details regarding the scientific process. She recommended the book Science in Action from Bruno Latour (1987) and stressed that we should read a lot and talk about our research as much as possible, first to the broader community and then in lay terms also to the general public.

Each presenting PhD student got upfront a mentor assigned who gave feedback to the presentation, but of course everyone in the audience was invited to ask questions and provide feedback. The presentations varied in quality and depth, but I think no one was able to present in the given time of 12 minutes (me included). It actually is a challenging task to present your whole PhD research within 12 minutes, especially if you are in an early-stage and it is just a plan.
The presentations were supposed to be accompanied by a poster presented in poster sessions in the coffee breaks. However, due to the fact that no one finished in time with the presentation, the poster session was moved to the general poster session of the main conference on Monday. Thanks to the chairs and local organizers to find some spare walls and arrange that we could present next to the main poster session.

A panel session rounded up the doctoral consortium. Several senior researchers discussed questions regarding the role of the PhD in industry, I will just briefly mention the questions and the main points:
- Which is your opinion with respect to this migration from academia to industry?”
- Higher salaries and more stability in industry
- Nowadays more opportunities in industry and a more research-influenced style of work
- On the negative side: whole research areas get confiscated by industry, e.g. information retrieval and NLP
- From your experience, which is the actual need of industries in terms of innovation? Are they really believing in it or it is just a trend that they want to follow?
- The industry wants simple things which work
- Companies need to stay ahead of competition
- May this new age of AI affect the programs of your PhD students?
- Putting PhDs on irrelevant topics makes also everyone unhappy
- We also benefit from it, e.g. knowledge embeddings, but one has to be careful because building a system by themselves is not research, how does it help our community?
- Do you think that a strong collaboration with companies would have a detrimental effect on the quality of research?
- A lot of tools we use nowadays are built by industries, we wouldn’t have build them for ourselves
- Industry brings a lot of insights
- Of course also the risk in credibility if too much research is directly funded by industry
Monday
At the first official conference day I participated in the opening session, the keynote by Dougal Watt, a session with industry talks and two sessions regarding data quality.
Opening session
Within the opening session it was stated that from 194 valid research track submissions 42 papers were selected and thus the acceptance rate of the research track was 21.6%. According to the presented statistics of submissions per topic in the research track (topics with more than 10 submissions) almost 80 submissions concerned database, information retrieval, information extraction and NLP. Whereas Ontology Engineering and ontology design patterns for the web are the topics with the least submissions in this more-than-10 category. It was a pity to see that the privacy topic was ranked in the statistics of topics with less than 5 submissions.

Congratulations to Olaf Hartig, Christian Bizer, Johann-Christoph Freytag to win the SWSA Ten-year award with their work “Executing SPARQL Queries over the Web of Linked Data”. Also congratulations to Julius Volz, Christian Bizer, Martin Gaedke and Georgi Kobilarov to also win the SWSA Ten-year award with their work “Discovering and Maintaining Links on the Web of Data”.
Keynote by Dougal Watt
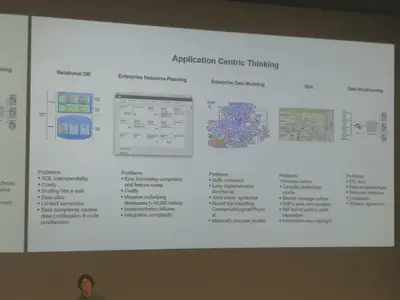
Monday’s keynote was given by Dougal Watt and was titled “Semantics: the business technology disruptor of the future”. He gave a small tour through the different eras of information processing: from pre-literate and literate via the printed word to modern computing, the web and context nowadays. Furthermore he talked about application centric thinking and about the different problems of relational databases, enterprise resource planning, enterprise data modelling, SOA and data warehousing. Summarized these problems mainly focus on limited semantics, massively complex models, interoperability and missing schema agreement leading to a 28 minute discussion about definitions within a 30 minutes meeting. Of course semantic technologies and ontologies offer a possible solution for these problems. But according to my opinion some of these problems still remain and are just shifted to how ontologies are modeled and how they are used, i.e. discussions of definitions and complex models.
Within the QA the topic data shapes and SHACL were brought up. Dougal said that SHACL shapes are fantastic things, as they can hide the complexity of ontologies which can then be used by businesses. Personally I find this a very interesting point which is also relevant to my PhD: Shapes become important components when working with ontologies and thus need also to be built systematically and/or considered when designing ontologies.
Presentations
Evgeny Kharlamov presented the work of colleagues regarding a knowledge-base for material science within the industry track. Working in material science involves the creation of new materials for which knowledge of thousands of existing papers and patents need to be searched. Queries such as which material X reacts with material Y and has its melting point below Z need to be asked. An ontology was designed and a knowledge graph was built to facilitate the task of this search scenario. Furthermore they are working on an end-to-end system including not only the ontology but also search interfaces for end-users. I was interested in how the ontology was designed to deal with that task: apparently a lot of subclass axioms were used. I like their use case in which they have to provide a user-friendly system powered by an ontology. As Dougal pointed out in his keynote: enterprise data modeling tend to create massively complex models. I would say that this enterprise modeling mindset still exists in the mind of some ontology engineers, a use case such as presented here shows that ontologies also have to be used by systems which also comes with extra requirements regarding their use.
Within one of the data quality sessions, I listened to Albert Meroño-Peñuela who presented the work of him and his colleagues about RDF-lists. MIDI applications (Musical Instrument Digital Interface) express songs as long lists of musical chords. In the context of this, the authors surveyed common list modeling practices taking e.g. different ontology design patterns for lists into account. The authors reported coherent results among triple stores when evaluating the triple stores’ performance when processing the different ways in which lists are currently represented. The rdf:List is the only expression which produces “closed” lists, but it is also the one with the poorest performance. It is interesting to see that certain design decisions have an impact on performance. It actually shows that guidelines of how to implement an ontology for a certain use case are needed to provide an optimal solution, i.e. in a use case in which performance is important the usage of rdf:List might not be optimal, whereas in a use case demanding more strict semantics the closeness of lists might be required.

Tuesday
For Tuesday I will discuss the keynote, panel session, PhD lunch, town hall meeting, gala dinner but also actual research sessions :-)
Keynote by Jérôme Euzenat
On Tuesday, Jérôme Euzenat presented the keynote For Knowledge. He quotes that data without knowledge is like a map without a legend and stresses that explicit knowledge is important. Also, a great idea remains a great idea. Sometimes the time for an invention has not yet come and reinventing the wheel sometimes makes sense respectively invent different variants of a wheel.

Another interesting idea he proposes concerns eScience. Nowadays scientific experiments can be described semantically: why not submitting a detailed experiment description to conferences/journals to receive reviews purely on the scientific process and not the outcome?!
Panel
After the keynote a panel session took place. It was titled “How much semantics goes a long way”, emphasizing on the how much with respect to the famous “a little semantics goes a long way” from James Hendler. Valentina Tamma, Jérôme Euzenat and James Hendler were the panel and the room was packed with senior SemWeb researchers. The audience lively participated in this panel discussion. I will briefly list some of the main comments.
- The past 20 years demonstrated that different ontologies in the same domain can exist, people choose what they want and one ontology possibly becomes the lingua franca of that domain
- There are obstacles; if technologies and languages are used which are too complex for people to use they won’t use it. That’s why expressivity might be reduced
- A way to achieve consensus is maybe a more expressive language to express nuance and isolate which statement you agree with and to which not. So you might end up to agree
- The problem is not about expressivity per se, but about the incentives to put the expressivity. E.g. in the research of genes, researchers put the expressivity in. We should ask, how to incentive the people to put the expressivity
- How much semantics is perceived wrongly, choose either to define less or richer expressivity, but it depends! For certain tasks we don’t need much expressivity. Focus should be to make these different types to coexist with the same data
PhD lunch
On Tuesday also the PhD lunch took place. This program point belongs to the Doctoral Consortium; PhD students and their assigned mentors should have a more informal environment to talk. I liked the setup, I was on a table with a few other PhD students and a few mentors. We could ask questions and a lively discussion was sparked. There were certainly very helpful tips, however given the time constraint we couldn’t reach a certain depth in the discussion so everything stayed more high-level.
Town hall meeting
The ISWC conference provides the town hall meeting as general session in which all kind of feedback can be provided.
One of the first points brought up was the review process. It was the first time that the research track was double-blind. Some people liked it and some not; there are certainly pros and cons but it was mentioned that better guidelines in how to review should be provided.
Another point of discussion was the location of the conference and thus the visa problematic a lot of attendees faced. The visa regulations of New Zealand were just recently changed so it couldn’t be taken into account back then when the conference venue was chosen. Unfortunately the university also had zero power in influencing the government’s visa decisions. Comments from the audience were among others that we should be more inclusive as a community and choose venues more wisely.
Session on ontology design
Two papers in this session gathered my attention, a paper regarding the detection of ontology design patterns in biomedical ontologies, and a spotlight paper about the use of OWL and WebProtégé at Pinterest.
Christian Kindermann presented how the influence of ontology design patterns in the biomedical domain can be measured. The presented results indicate that there does not seem to be much use of ontology design patterns in the analyzed ontologies. However, regardless of the results this is very interesting research as it provides a baseline which allows further investigation. One introduced way to detect ontology design patterns is by checking first if a specific axiom used by a pattern is present in an ontology. This indirect way to conclude if an ontology design patterns is present in an ontology can be facilitated by our MontoloStats dataset/webservice on which we recently published a paper.

Rafael S Gonçalves presented how an OWL ontology and the use of WebProtégé drastically shortened the development cycle of the Pinterest taxonomy. The Pinterest taxonomy contained around 6,000 “interests” users can have which were arranged in 3 layers. This taxonomy was increased to 11,000 interests represented as OWL classes organized in 12 layers. It took less than 2 months to build the end-to-end system the Pinterest employees without any ontology experience can use. Furthermore it took less than 1 month to build the final ontology. I would say that OWL is often perceived as very complex, but this presentation shows that with the use of appropriate tooling such as WebProtégé, which offers collaborative features and complete provenance, even non Semantic Web experts can handle an ontology! A question asked by the audience further gathered my attention: why did you use OWL and not just SKOS? Apparently there are future needs which can be addressed by OWL, especially the implementation of existential restrictions. I find this particularly interesting as it shows that there exist specific needs for certain restriction types which is relevant for my PhD and the definition of guidelines in how to model restrictions.
Session on domain ontologies
Within this session I liked the talk from Karl Hammar about a Real Estate ontology and the talk about the W3C recommended SSN ontology.
Real estate data are not just about prices, there are also needs regarding energy efficiency, maintenance and sustainability. Karl Hammer presented a real estate ontology which was built following an adapted version of the eXtreme Design methodology. The ontology consists of a core and different modules and it deliberately renounces the reuse of foundational ontologies. I like that he emphasized that an ontology is useful but not enough! There must be also a way to interact with it, i.e. the ontology has to be used. Short after the conference, Karl released a first version of a tool to create a OpenAPI specification from an OWL ontology. Cool stuff 👍

The SSN ontology is a W3C recommendation to model sensor data. Kerry Taylor presented the work around the SSN ontology. Interestingly, not only the SSN ontology was built but several best practices were published under the umbrella of W3C. I have read a journal paper related to this talk, it discusses design decisions to make the initially defined data model easier. This was achieved by modularizing the ontology into a “lightweight” core and outsource alignments to other ontologies into specific modules. The core ontology mainly defines concepts and no axioms, even to determine domain and range schema.org’s domainIncludes and rangeIncludes are used. In my opinion the presented solution solves a lot of problems and demonstrates how a trade-off between strict semantics regarding interoperability to other standards and lightweight description of concepts can be achieved!

Gala dinner
Besides all the research the conference of course also provided a lot of room for social gathering :-) On Tuesday’s agenda was the gala dinner. A Māori ensemble performed several songs and traditional dances to welcome the ISWC participants from all over the world to New Zealand! The Māori are the indigenous people of New Zealand which inhabited the islands roughly 700 years ago. This is also interesting as it means that New Zealand was the last place on earth on which the Homo Sapiens settled down, just a few hundred years ago! After that we enjoyed our food to which also the ice-cream kiwi from the blog posts header image belongs.

Wednesday
The last day was shorter, my highlights are the keynote, a presentation about ontology ranking within a search scenario and the closing ceremony.
Melanie Johnston-Hollitt gave the keynote Extracting Knowledge from the Data Deluge to Reveal the Mysteries of the Universe. This keynote was very interesting as it revealed a lot of really cool scientific applications which could profit from explicit knowledge. I can only recommend to listen to the keynote which is available on YouTube.
Short before Lunch I listened to some talks regarding ontologies for recipes and food. This seems very interesting and I’m happy some efforts regarding this direction already exist.
In the last talk I’ve heard at ISWC 2019, Niklas Kolbe talked about the ranking of ontologies regarding relevancy when searching for concepts. He pointed out that people have a certain trust into the first few search results and hence a ranking plays a crucial role. In the already mentioned recently published paper we argue that for an ontology reuse scenario the search for ontologies containing certain axioms might be relevant. It was interesting to hear that something like our solution could be integrated into the presented solution based on qualitative features.

In the closing event best papers in several categories were awarded, I will not list all the winners, just a general “congratulations”! 😃
The next ISWC conference will take place in Athens, Greece. In 2 years ISWC will take place in Albany, USA. The audience seemed not that enthusiastic when this venue was announced, .. maybe because of the already mentioned issues with visas for certain countries such as the US.
That was the ISWC 2019 conference from my point of view, I hope you enjoyed reading it! I got a lot of feedback for my PhD and also saw the relevancy for it.
I was writing this blog post while traveling around in New Zealand, I will now enjoy the remaining time in New Zealand, see you at the next conference!
