
In the old days, research was done by famous individuals. Nowadays, research is a team effort! Working together requires making agreements about how to collaborate and using common tools. These kinds of agreements (or standards) and tools are especially crucial given the amount of data nowadays. Me and around 700 other people attended the 2nd Conference on Research Data Infrastructure, in Aachen, Germany from August 26 to 28, 2025. In this blog post I will reflect on the various presentations and posters I saw as well as the discussions I had.
Context
In August 2025, the German National Research Data Infrastructure (NFDI) organized the second edition of the Conference on Research Data Infrastructure (CoRDI). Around 700 people attended this international multi-track conference. This year’s edition did not follow a standard peer-review, but was curated based on the conference organizers and a balance of the various disciplines and topics in the field of research data infrastructure.
Even though my contribution was not selected, I anyway attended the conference as this is a great chance to network. Next to the small things, such as live music from the RWTH Aachen big band, the daily buffet with default vegetarian/vegan options, and exciting robot demos at the social event, the conference featured Research Data Management (RDM) in various disciplines.
My main takeaways
-
Standards and identifiers are the hidden champions: Whether in workflows, Knowledge Graphs, or infrastructures, persistent identifiers and authority data are the backbone that allow collaboration across disciplines.
-
Infrastructure is both technical and human: Behind cables, servers, and workflows, it’s people, governance, and communities that keep infrastructures alive.
-
Bridging scales is key: The inspiring keynote reminded me how crucial large-scale infrastructures and global governance are. But in the sessions and posters, I also saw how much progress depends on practical tools, workflows, and community initiatives that researchers can actually use today. The real challenge is linking both scales together.
Even though in the rest of this post I will only focus on my personal main highlights it is still a quite lengthy post. Feel free to immediately jump to the last section on my reflections or other sections that interest you by using the table of contents below.
Inhaltsverzeichnis
Keynotes
This year’s conference featured two keynotes: Rob Finn talked about the complex data ecosystem of life science data and Cathrin Stöver provided insights into the physical networks that make all of our work possible in the first place.
Rob Finn - Life Science data
On the first conference day, Rob Finn from the European Bioinformatics Institute talked about the kind of data that they process and publish. As well as where he sees potential for AI.
According to Rob, and hinting towards work of Carole Goble, there are ad-hoc workflows which can be made FAIR by describing them with Ro-Crate and uploading those descriptions to the WorkflowHub.
It’s not really my domain, but what I take home from Rob’s talk is the evolution of workflows. Because I recognized my work for the BELTRANS project, where we create a corpus of book metadata of contemporary translations between Dutch and French. It’s a completely different area, but in our case we also start with a bunch of Python scripts, glued together with bash scripts.

Cathrin Stöver - Research and Education Infrastructure
In her impressive keynote on the last conference day, Cathrin Stöver the Chief Communication Officer at GÉANT, discussed how GÉANT provides global connectivity for researchers.
She wasn’t referring to a few online services or cloud solutions. She discussed real-world 800 GBit traffic via GÉANT’s own submarine cables, as well as other success stories, such as the well-known eduroam Wi-Fi internet access service.
GÉANT provides research and education network services by interconnecting 38 National Research and Education Networks (NRENs) such as Deutsches Forschungsnetz (DFN) in Germany or BELNET in Belgium and serves around 50 million users across Europe. In the last 15 years, other parts of the world have been connected as well, such as East Africa extensively and West Africa to a lesser extent.
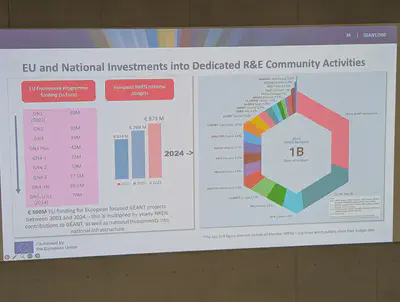
In addition to these interesting facts, the keynote also focused on the conference organizing organization NFDI. It must undergo evaluations and needs to become operational within a few years. Based on GÉANT’s experiences, Cathrin identified three important aspects for success: validation, people, and funding. GÉANT receives top-down and bottom-up validation from both its users and recognition on policy level, including an alignment with the Sustainable Development Goals. Evenly important is the people aspect with a strong community and regular community conferences. But also having a value conversation to keep people with passion. And last but not least, the aspect of secure and sufficient funding, which due to the multiplier effect pays off.
If you ask me, I think NFDI is on a good way! There is a large user base and recognition from the policy level, both from the German government as well as via links to European research. I have also met many passionate people at the conference. And at least from an outsider perspective, I think lots of money is invested in Germany for RDM at the moment.
Persistent identifiers, Authority data & Knowledge Graphs
If there’s one area at CoRDI that resonated most with my own work, it was the trio of persistent identifiers, authority data, and knowledge graphs. They are deeply interconnected: identifiers give us stable references, authority files give meaning to those references, and knowledge graphs weave them together into broader ecosystems.
PIDs: Small links, big impact
Every Knowledge Graph or authority file starts with the simplest building block: a persistent identifier. Several posters and discussions at CoRDI showed just how central PIDs have become.
Unfortunately I missed the PID panel, because it was scheduled in parallel to the humanities and authority files session But thanks to the poster sessions, I could speak with experts directly. For example at the poster of Barbara Fischer from the German National Library (DNB) and Paul Vierkant from DataCite about the PID network Germany.

We don’t have something similar on national level in Belgium yet, (probably also due to the special federalism in Belgium), but I’m glad that my colleagues from the FedOSC project are also looking into the PID topic, at least for the Federal Scientific Institutions! While talking about PIDs, we were also joined by Daniel Mietchen, who argued that Wikibase already comes with PIDs out of the box.
But identifiers on their own are just strings (or ideally Uniform Resource Identifiers (URIs)). Their real value comes when we use them to describe entities such as people, places, or works, which is where authority data comes in.
Authority data in the humanities
Authority files give identity to PIDs, turning abstract identifiers into meaningful references for people, places, and works. The humanities session at CoRDI highlighted how this plays out in practice.
The humanities session featured talks about the Gemeinsame Normdatei (GND), which is the authority file of German-speaking countries, and the Knowledge Graph software Wikibase.
In the presentation, Authority Files and the Text+ Data Space (10.5281/zenodo.16736146), Barbara Fischer highlighted that
“standards are not dropping from the sky”
Furthermore, she argued that we should not lose diversity when using standards. Barbara used English as an example of a language used for understanding each other in science. However, it does not replace one’s mother tongue, with which one can express much more diverse concepts. Barbara further argued that we have to give people the edit button, or at least a button to suggest changes, this will also enhance collaboration.
Open Knowledge Graphs are one way to enable (large-scale) collaboration. While most people are familiar with Wikidata, there are also lesser-known, more domain-specific Knowledge Bases. One such example is the FactGrid Wikibase instance, used by many historians. Because the historians share a single Wikibase instance, they are also forced to work together.
FactGrid’s creator, Olaf Simons gave the presentation Wikibase - the best software to communicate with the upcoming knowledge graphs? (10.5281/zenodo.16892677). In it, he states a very concrete issue: the 100 million item limit of Wikidata’s (and Wikibase’s) Blazegraph triple store! Apparently the Wikidata graph was split as a workaround. Yet, Olaf argues that these kind of workarounds do not solve the underlying issues. He calls for the simple but effective solution:
“The NFDI should develop a joint interest with Wikimedia Germany to break the present 100 million item limit”

I can very much relate to Olaf’s statement. As a computer scientist I am used to developing custom software solutions when I cannot find standard software that addresses the problem. I often see software developers in different (engineering) fields develop software even when standard software is already available. One example is software to generate RDF from other data sources. Standard software is important! In the humanities, for example, where tools with a user interface and a high Technology Readiness Level (TRL) are needed, Wikibase plays an important role. This fundamental software should be maintained and further developed to overcome its current limitations.
Authority files create structure, but once we start connecting them across domains and datasets, we step into the world of Knowledge Graphs and ontologies.
Knowledge Graphs and Ontologies
Knowledge Graphs are where identifiers and authority files come together, enabling connections across datasets and disciplines. At CoRDI, I saw many examples of both the opportunities and the challenges of building such ecosystems.
In the humanities session, Florian Thiery and Lozana Rossenova presented challenges of federated queries using the Wikiverse and OpenStreetMap within the NFDI Knowledge Graph Ecosystem (10.5281/zenodo.16736048). While doing federated SPARQL qeries across Wikibase instances, including FactGrid, they noticed technical and conceptual hurdles, such as namespace collisions, property mappings or allow lists. The latter specifying which other Wikibase instances can be accessed by federated queries.
On the last day of the main CoRDI conference,
Lozana Rossenova
also presented the results of a survey about
how NFDI consortia are using Knowledge Graphs (10.5281/zenodo.16736078).
The survey was conducted between March and May 2025
and covered 27 Knowledge Graphs from 11 consortia.

For their presentation, the challenges were grouped into four larger categories. To me, it looks very familiar. Anyone who starts working with Knowledge Graphs will eventually face one of these challenges. We cannot overcome every challenge in a generic fashion. I believe we should curate best practices related to these challenges and create teaching materials from them.
Volker Hofmann presented the Helmholtz Knowledge Graph (10.5281/zenodo.16736336). I liked the used images of the presentation, such as the following about separated islands of data. Apparently only a small percentage of all the entities.

This made me think about the many authority records in MetaBelgica for which we only have a name and no linked birth/death dates or birth/death places. In our source data we have linked publications though, instead of leaving them out, we maybe should add some linked PIDs, ISBNs or publication places to MetaBelgica to not create authority islands…
In Sarah Rebecca Ondraszek’s presentation on the NFDI4Memory Knowledge Graph (10.5281/zenodo.16736125), I found two things interesting. First, they do not yet have a link with PROV-O, because of the more difficult alignment with BFO (yet there could be mappings). Second, they mentioned Sampo, a Linked Data publishing tool from Finland, that I have recently seen at various conferences. We are testing it for the BELTRANS project as well, and I know that the Sampo team is collaborating with the CLARIAH-VL+ project in Flanders/Belgium to improve the software (Sampo fork from the Ghent-Centre for Digital Humanities that will be rebased to the original Sampo).

During the Q&A of Julia Thoennissen’s presentation about FAIR and scalable access to large image data in the range of petabytes (among others in neuro science) (10.5281/zenodo.16736220) I wondered if their workflow, which contains 3D images, could be extended with the International Image Interoperability Framework (IIIF) for data publishing. This would provide a standard software solution instead of a custom one. The authors were not familiar with IIIF, it’s probably less well-known outside of the cultural heritage domain. Afterwards I had a look myself, there is a 3D community working group at IIIF. However, based on the community group’s current description it does not seem that this feature already exists.
At the poster of the NFDIcore 3.0 ontology, I also had a small chat with Jörg Waitelonis about the BFO basis of the ontology (10.5281/zenodo.16736251). We talked about the possibilities of the ontology to also model temporal aspects, such as names that change over time. Which comes with a lot of extra triples (in case this is done for many entities).

In the presentation of Leyla Jael Castro about Bioschemas and Schemas.science at NFDI (10.5281/zenodo.16735850), I have learned about Bioschemas and Schemas.science. The first is a is a community-driven initiative to build upon Schema.org for the life science domain. The latter is a sister website in which they broaden the Bioschemas efforts to a more general research-related extension for Schema.org. In both cases to enhance findability, as Schema.org is mainly used by search engines.
AI
It’s 2025, of course there has to be at least one session about AI! Sandra Geisler introduced the AI session, by mentioning current barriers for FAIR Research Data Management, and for which barriers AI can help.

For me it’s also not only about how AI can help RDM, but also how RDM can help AI. I forgot who said it, but someone at CoRDI remarked that Ontologies and the Semantic Web are the ground truth to make AI creative. I find this a very spot-on statement, because machine learning without annotated data is just pattern-finding. To move beyond that, we need humans and semantics: structured knowledge that gives AI something meaningful to work with.
Other AI-related talks and posters at the conference focused on different aspects to annotate machine learning models. To this regard I have learned about things like FAIR4ML, a vocabulary to describe Machine/Deep Learning models (10.5281/zenodo.16735334), presented by Leyla Jael Castro, or MLentory, a registry for Machine/Deep Learning models making use of FAIR Digital Objects (10.5281/zenodo.16735316).
One presentation also mentioned an AI product, that can generate a conversational podcast out of a research paper. So you hear artificial voices having a chat about the topic. The presenter said that after listening to the podcast, one interesting thing was that the AI podcast contained examples that were not in the paper, but which the author deemed interesting examples as well. That sounds amazing to me, I have the feeling that this can revolutionize scientific communication.
Infrastructure
One part that is utterly important, and leans towards the impressing keynote, is actual physical infrastructure. With all the existing clouds, data spaces and services, I’m often wondering where the stuff is actually hosted. Who pays for it and for how long will the services stay online?
At the very basis we have the NRENs from GÉANT, thus for example BELNET in Belgium. And via procurement one can get access to virtual machines for example via the OCRE programme at data centers of partners.

In the context of the NFDI, base4nfdi provides higher level services such as jupyter4nfdi. At the poster of base4nfdi, Martin Reinhardt explained to me how the jupyter4nfdi works. It is essentially a JupyterHub hosted at Forschungszentrum Jülich and another data center. Research institutions can host their own Jupyter services, creating a decentralized network that researchers can access via the central JupyterHub and Single-Sign-On. This way, research institutions can configure their settings so that only their own researchers can use the Jupyter resources from the institution’s servers, for example. However in theory, researchers from other institutions could also use the provided resources. According to Martin, this is also in the interest of cloud providers, because they usually want at least a certain percentage of server load; otherwise the infrastructure just sits there and costs money.
Eventually, research institutions still provide the actual infrastructure, or at least pay for virtual machines in the cloud. This brings us back to the initial question: Who pays for it, and for how long will the services stay online? This obviously depends on the research institutions, but I think it will likely be project-based funding after all.

While not ideal, there are real-life examples of successful infrastructures that prove such funding can work. For example, historians can use FactGrid to store their data even after their funding period ends. In Flanders, I came across the ODIS platform, which also offers a home for research data within its scope. For the latter I also have heard that researchers already started to mention this platform (or repository) in their mandatory data management plans.
Technical infrastructures are impressive, but they rely on more than cables and servers. Agreements, policies, and shared responsibilities - in short, governance - are what make these systems sustainable.
Governance
When we talk about infrastructure, we inevitably end up talking about governance: the agreements, rules, and decisions that make collaboration possible. Networks don’t just run on cables and servers, they run on policies, contracts, and trust. This theme surfaced repeatedly, from the inspiring keynote to lively panel debates and practical project presentations.
Global governance
They keynote of Cathrin about global connectivity obviously is also related to global governance, which is not an easy topic in today’s geopolitical reality. This was the main subject of the keynote’s Q&A, with questions relating to why certain parts of the world are not connected (GÉANT’s headquarters are in Amsterdam, so it falls under Dutch and European law and is forced to follow sanctions) and why satellite networks are not used instead of terrestrial networks (there is no low-orbit capacity yet owned by Europe, and high orbit does not provide enough bandwidth).
A related perspective came up in the resilience panel: the reminder that researchers are citizens of science, not citizens of a country. Infrastructure cannot be shielded from geopolitics, but the research community aspires to build connections that transcend national borders.
This perspective was underlined by the example of PANGAEA during the resilience panel. It stepped in to safeguard research data that risked being lost due to shifts in U.S. policy. Here governance became a matter of resilience: ensuring that research data remain accessible for the global community, even when political frameworks change.
Governance in practice
Governance is also a topic on a much more practical level, related to data stewardship.
Robert Herrenbrück presented a poster about the establishment of a central helpdesk for KonsortSWD (NFDI4Society), (https://doi.org/10.5281/zenodo.16735332) illustrating governance through support: coordination and service structures that help researchers navigate responsibilities without losing sight of their own work.
Somewhere between the crowded poster stands, I found myself in a memorable discussion that perfectly captured some practical governance challenges. The discussion was aboutt templates for data sharing agreements. Someone mentioned that when adapting the template to their needs and referencing the original template, they often get feedback such as “the template is different, why did you deviate from it?”. I think this highlights that while templates provide a much-needed baseline, they shouldn’t become rigid dogma. Real collaborations need room for adaptation, and governance should support flexibility rather than punish it.
If governance defines the rules and structures that make infrastructures sustainable, communities are the people who put these rules into practice, train new researchers, and ensure that collaboration thrives.
Training & Communities
While governance sets the framework, it’s the communities of researchers, data stewards, and trainers who bring it to life. From workshops to collaborative projects, these people ensure that research infrastructures are not just functional, but actually usable and sustainable.
As an outsider I must say that I am impressed about all the different initiatives represented at CoRDI. Through discussions at the conference I have learned that there are also other non-NFDI initiatives in Germany, some of them older than NFDI. For example the different federal state RDM initiatives like bwFDM (shout out to The Länd) which also had posters this time. They jointly presented themselves on the last CoRDI in 2023 (10.52825/cordi.v1i.242, see also my previous conference report 10.59350/pg3xj-4z449).
Other initiatives are the Fachinformationsdienste (FIDs), that in its current form receive funding since 2014. I personally know the thematic FIDBenelux as it relates to Belgium and because they are also in the follow-up committee of the MetaBelgica project. At CoRDI, Reinhard Altenhöner and Jana Fabrizius presented about the Role of FIDs Between Disciplinary Research and National Infrastructure (10.5281/zenodo.16736302). I have learned that since 2018 FIDs are self organized and currently have long-term funding via FIDPlus.
Regarding RDM training, two posters stood out to me as memorable and insightful. One covered the general aspects of collaboration, and the other covered the CARE principles.
The poster Lost in Collaboration really hit the nail with the identified difficulty for effective collaboration:
“Turning Collaboration into Concrete Outcomes.”

At the second poster I joined an interesting discussion about the CARE principles. Josef Jeschke explained that apparently there is no clear definition in CARE about indigenous, for example, it does not have to be a minority. In general I find the ethics aspect of CARE interesting, so I am wondering if it could be applied even in non-indigenous use cases. More info on their poster The Informed CARE Data Steward. Ways to CAREification: https://doi.org/10.5281/zenodo.16736131.

Reflections & Takeaways
Looking back at CoRDI 2025, I was struck by how often the same themes surfaced across very different tracks. Whether we were talking about workflows in the life sciences, authority files in the humanities, or large-scale infrastructures, the same questions kept coming back: how do we connect, how do we sustain, and how do we collaborate?
I’m glad that this community exists. PIDs and standards are probably not the most exciting topics, but they are key and enable so much more! So far we are preaching to the choir, but according to me, research infrastructures must enter main stream discussions. It’s not just about some tools or consortia, it’s nothing less than a shift in how research and research training works. And due to the scaling this also should be a shift in how funding schemes work and how we train new generations of students and researchers.
If there is one thing missing at CoRDI, it is more European and international contributions. But I think we are on a good way. During the open panel discussion about how to measure the success of NFDI, Joanne Yeomans from the Dutch Thematic Digital Compentence Centre, publicly brought up something that I was thinking as well: the success of NFDI is that NFDI is there in the first place!
We, from other European institutions can reference to the NFDI/CoRDI, simply because it exists. Even if it would be only a small initiative it would already be great, but the scale of NFDI makes it even better: all applied research and lessons learned stem from collaborations of all major universities and research institutions of the most populous country of the EU.
Or in the words of the keynote speaker Cathrin Stöver
a community needs it conference.
I hope CoRDI will become the research infrastructure conference, beyond NFDI. Hopefully see you all at the next CoRDI!
References
- Fischer, B. K., Eckart, T., Körner, E., Buddenbohm, S., Al-Eryani, S., & Gradl, T. (2025). Authority Files and the Text+ Data Space. Zenodo. https://doi.org/10.5281/ZENODO.16736146
- Simons, O., & Moeller, K. (2025). Wikibase - the best software to communicate with the upcoming knowledge graphs? Zenodo. https://doi.org/10.5281/ZENODO.16892677
- Thiery, F., Rossenova, L., Mietchen, D., Homburg, T., & Thiery, P. (2025). Distributed Research Data Knowledge Graphs - Challenges of federated queries using the Wikiverse and OpenStreetMap within the NFDI Knowledge Graph Ecosystem. Zenodo. https://doi.org/10.5281/ZENODO.16736048
- Rossenova, L., Limani, F., Fortmann-Grote, C., Kaplan, A., Thiery, F., Latif, A., Shigapov, R., Zapilko, B., Schubotz, M., Fliegl, H., & Tietz, T. (2025). How are NFDI consortia using Knowledge Graphs?: An overview of common functions and challenges by the Working Group “Knowledge Graphs”. Zenodo. https://doi.org/10.5281/ZENODO.16736078
- Hofmann, V., Soylu, M., Preuß, G., Fathalla, S., Kulla, L., Dmello, F., & Sandfeld, S. (2025). The Helmholtz Knowledge Graph - towards a Helmholtz FAIR data space. Zenodo. https://doi.org/10.5281/ZENODO.16736336
- Ondraszek, S. R., Tietz, T., Posthumus, E., Fliegl, H., Waitelonis, J., & Sack, H. (2025). Indexing Historical Research Data: MemO and the NFDI4Memory Knowledge Graph. Zenodo. https://doi.org/10.5281/ZENODO.16736125
- Thönnißen, J., Oliveira, S., Oberstrass, A., Kropp, J.-O., Gui, X., Schiffer, C., & Dickscheid, T. (2025). A Perspective on FAIR and Scalable Access to Large Image Data. Zenodo. https://doi.org/10.5281/ZENODO.16736220
- Waitelonis, J., Tietz, T., Beygi Nasrabadi, H., Bruns, O., Posthumus, E., Fliegl, H., & Sack, H. (2025). NFDIcore 3.0: A Mid-Level BFO2020-Compliant Ontology for Sustainable Research Data Interoperability Across Consortia. Zenodo. https://doi.org/10.5281/ZENODO.16736251
- Castro, L. J., Gaignard, A., Juty, N., Schnitzer, H., Reed, P., & Goble, C. (2025). Bioschemas and Schemas.science at NFDI. Zenodo. https://doi.org/10.5281/ZENODO.16735850
- Solanki, D., Ciuciu-Kiss, J. T., Quiñones, N., Ravinder, R., Venkatesh, S., Rebholz-Schuhmann, D., Garijo, D., & Castro, L. J. (2025). FAIR4ML, a vocabulary to describe Machine/Deep Learning models. Zenodo. https://doi.org/10.5281/ZENODO.16735334
- Quiñones, N., Geist, L., Ravinder, R., Solanki, D., Venkatesh, S., Rebholz-Schuhmann, D., & Castro, L. J. (2025). MLentory: NFDI4DS registry for machine learning models and related artifacts. Zenodo. https://doi.org/10.5281/ZENODO.16735316
- Herrenbrück, R., & Bayer, S. (2025). Establishing a Central Helpdesk for KonsortSWD - NFDI4Society: Goals, Challenges, and Solutions. Zenodo. https://doi.org/10.5281/ZENODO.16735332
- Brand, O., Bruhn, K., Cyra, M., Fingerhuth, M., Gerlach, R., Jacob, B., … Weiner, B. (2023). The Federal State Initiatives for RDM as Intermediaries in a Dynamic Landscape of RDM Infrastructures and Services. Proceedings of the Conference on Research Data Infrastructure , 1. https://doi.org/10.52825/cordi.v1i.242
- Lieber, S. (2023, September 17). CoRDI 2023. Posts | Sven Lieber. https://doi.org/10.59350/pg3xj-4z449
- Altenhöner, R., & Fabrizius, J. (2025, August 4). Bridging Communities: The Role of FIDs Between Disciplinary Research and National Infrastructure. 2nd Conference on Research Data Infrastructure (CoRDI), Aachen, Germany. https://doi.org/10.5281/zenodo.16736302