
At the end of November 2019 I could visit the sunny California to attend the Conference on Knowledge Capture (K-Cap). A lot of interesting workshops, tutorials and talks covered topics such as the representation of knowledge in Wikidata, approaches to transform tabular data to Linked Data, or the representation of scientific literature and processes as Knowledge Graphs. Additionally I could present our work on MontoloStats. Continue reading for the full trip report!
The International Conference on Knowledge Capture (K-Cap) takes place every two years alternating with the EKAW conference. This year it took place in Marina Del Rey, CA in the United States. I traveled directly from New Zealand were I attended the ISWC conference a few weeks earlier.
What I liked the most K-Cap is a single track conference and thus you can’t miss any talk because of another one.
What I didn’t like It is interesting that K-Cap is not only about Semantic Web stuff but knowledge capturing from a general perspective also including NLP and machine learning. However, for me some of these talks were hard to grasp and were not directly related to my research.
Talks regarding “Concept embeddings” seemed to be very present, but since this topic is not too relevant for me I’ll skip those in this report 😃. Instead in this post I will mainly focus on talks from the following topics which also seemed to be very prominent:
- Wikidata
- Languages and approaches to map tabular data to Linked Data
- Knowledge Graphs of scientific practices or literature
SciKnow workshop
On the first day I attended the Third International Workshop on Capturing Scientific Knowledge (Sciknow 2019). Yolanda Gil gave a very interesting keynote about the capturing of hypotheses and scenarios in scientific research. “Hypotheses are not finished after a paper is accepted” she said, the confidence value of the hypothesis changes over time. New and/or more test subjects might be available later. Additionally there are also other methods available to evaluate a hypothesis even though some labs might use the same or similar methods just because they were always used. I think we should definitely keep track of our hypotheses, methods and results in a systematic fashion: We are scientists in the end, future research from different angles might bring new insights on the current state of knowledge in our community!

Allard Oelen talked about the annotation of scientific literature using crowdsourcing to easier compare scientific contributions. It is difficult to find crowd workers qualified for such a task, additionally it is very time consuming as a scientific paper first has to be understood. Thus Allard and his colleagues aim for a system in which the authors annotate their papers while submitting. Ideally this should take less than 10 minutes of the authors’ time. It is a very intersting approach, but authors might submit only the bare minimum information when provided with a template during paper submission. I think a gamification approach could here be of help, i.e. showing additionall information based on the Knowledge Graph’s statistics, such as “x% of authors also filled in this form field”.

Oscar Corcho presented ongoing work from Ana Iglesias Molina about using spreadsheets to declaratively express Linked Data mappings which then can be translated to the most suitable language. Starting point of the presented work is the Bio2RDF dataset which contains biomedical knowledge; how is it generated?, is it still up to date?. Based on experience in working with different domain experts, spreadsheets have proven to be a good way to represent information. It is an interesting approach and distantly reminds me a bit of the tabOTTR representation of the ontology template language OTTR.

In classical Linked Open Data, Linked Data is generated and then linked. Daniel Garijo presented WDPlus which follows a link-first approach, different domain-specific satellites are created around the Wikidata core.
Some of these satellites might be based on tabular data. Different languages such as R2RDF and RML exist to transform structured data to RDF. However, especially in spreadsheets domain experts use a variety of layouts to represent the data which poses challenges. Therefore WDPlus has the T2WML framework, using YAML to express the transformation from tabular data to Wikidata. These mappings makes use of YAML which apparently is human-friendlier, something which I’ve seen in other approaches too. I like the idea of the “link-first” approach, it reminds me of Ontology Engineering where existing classes and properties should be reused as much as possible. In fact, also the challenges described by Daniel are similar, i.e. the identification of new properties which is currently performed manually by knowledge engineers, namespace issues and inter-satellite links.
Wikidata tutorial
In the afternoon of the first day I attended the Linking, Extending, Exploiting and Enhancing Tabular Data with Wikidata tutorial given by Daniel Garijo and Pedro Szekely. I finally learned the basics of Wikidata and its data model which differs from e.g. the one from DBpedia.
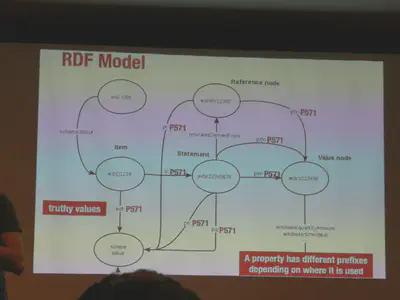
Wikidata is a collection of claims whereas each claim has related qualifiers and references.

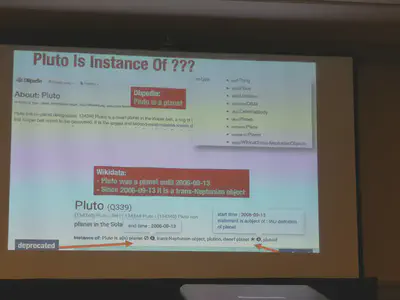
Since Wikidata is using a role model it can represent information more accurrate as e.g. DBpedia. In DBpedia Pluto is still a planet, whereas in Wikidata it is stated that it was considered a planet in a certain period but now not anymore.
The following picture shows some stats about the concept hierarchy in Wikidata. It also shows the very nice output of a commandline tool showing the hierarchy with attached stats.

However, the mapping of the Wikidata data model to RDF looks complex in the beginning, i.e. each Wikidata statement is expressed using multiple triples as reification has to be used. Please note also the different namespaces.
According to GoogleTrends and statistics published by Wikidata it gained a lot of attention in the recent years. The role-based model with qualifiers and references looks very interesting, also the fact that Wikidata is a huge crowdsourcing project. I wonder how easy or hard it would be to adapt or develop certain Ontology Engineering activities suitable for Wikidata.
First conference day
Peter Clark from the Allen Institute of AI gave the keynote of the first conference day. He introduced the project Aristo which is about reasoning and explanation.
“Tables are a way to express systematic knowledge, e.g. in science” he said. Peter talked about so called table knowledge systems which are also used in the backend of the Aristo system. Knowledge is then extracted from these tables to execute table reasoning. It is interesting to see that there are more approaches than only node-link-based Knowledge Graphs. This table-based solution performs quite good in different challenges. The Aristo question answering system outperforms an average 8th grader.
Later that day I had the chance to present our work on MontoloStats which apparently sparked some discussions among the reviewers and thus was marked a spotlight paper because it was controversial.
Looking back at the first K-Cap 2001 I initially asked the question how we model knowledge nowadays were we have hundreds of ontologies and dozens of W3C recommendations available at our finger tips. I presented our approach to create a statistical dataset about the use of different OWL axioms in ontologies extracted from LOV and BioPortal. Concretely we are looking into how such statistical metadata can improve the process of ontology reuse, but beyond that, the dataset provides empirical data providing several insights and raises new questions to research. I am lucky about the feedback I got. Specific tools like Protégé or visualizations like VOWL might focus too much on certain restriction types and thus seduce users to use these more often than others. Although marked as controversial, the audience seemed to appreciate the fact that there are now openly available empirical data about the use of axioms in ontologies. For me such axioms are just one way to express restrictions, limiting conditions imposed by the real world or use case. Let’s see where my research towards better modeling guidelines to express restrictions will lead me 😃.
Town Hall meeting
In the town hall meeting it was announced that Oscar Corcho becomes the new chair. Furthermore the location and duration of the conference, as well as the review process and list of topics were discussed.
The audience seemed to prefer larger cities over isolated areas as the traveling becomes easier. Although it was pointed out that the sessions were quite packed with presentations, the 2-day duration is preferred over 2.5 days. Also given the fact that the last half day of a conference some people leave earlier anyway.
Whereas long papers were accompanied by a presentation, short papers had a poster. It was pointed out that a short paper is not shorter in research and that the posters should also be visible for the duration of the entire conference.
Since the review phase was in August (vacation period) it was difficult, but generally everybody was happy with the reviews. Something like a best reviewer award was also proposed to give further incentive for good reviews.
The shepherding process for certain papers was also appreciated although it gave an extra burden to reviewers and meta reviewers as an answer letter and resubmitted paper needed to be checked again.
For the future the list of topics might also undergo a small change.
The venue for the next K-Cap will be … announced.
Second conference day
Due to a project meeting I unfortunately missed the keynote and most of the talks of the morning. Even a single-track conference can’t help much in such a case 😃.
In the afternoon Cristina-Iulia Bucur talked about the review process in science which didn’t really change much the past few hundred years. Currently she and her colleagues are looking into ways to improve the reviewing process by using Semantic Web technologies. Reviews and concerned text passages are expressed as Linked Data, additionally reviews can be further annotated to e.g. say if it concerns grammar or content. A user study was performed to evaluate the proposed fine grained review data model. Looking at how the review process works, I wonder why nobody ever changed it. I think even in a pre-semantic-web era other tools could have been used to improve the review process. In the here proposed solution I especially like the UI in which the review is directly attached to the text, so researchers can review while reading.

Binh Vu talked about the language D-REPR to map tabular data with different layout to RDF. Based on openly available tabular data extracted from data.gov it was verified that the language meets stated requirements. Additionally the performance was evaluated by comparing the execution of the Rust-based implementation of D-REPR against two other solutions on data in the nested relational model layout. There are many languages and tools to transform tabular or any structured data to RDF. A discussion after the talk revealed that instead of creating new languages and tools the existing recommendations should be updated, taking current limitations into account.

I’m currently looking into visualizations for RDF data, thus I found the talk of Vitalis Wiens also very interesting. He presented GizMO, a methodology and tool to visualize ontologies. It is based on an ontology which addresses the graphical appearance of OWL constructs in one layer, and visual properties for conceptual elements in another layer. Great work! I am not aware of any ontology to describe the visual appearance of graph based models. Additionally nested visualizations like UML are also mentioned in the paper and can be generated in the demo. I’m pretty sure this work will be relevant for a lot of visualizations out there and can also serve as a common format to interchange visual information.

Closing event
Within the closing event, Ling Cai was awarded the best paper award for the paper TransGCN:Coupling Transformation Assumptions with Graph Convolutional Networks for Link Prediction. Congratulations!
This was K-Cap 2019! I enjoyed the many conversations I had. Additionally I also had my first main track presentation. I will definitely have a look into Wikidata and will also follow up on some of the presented papers. I’m looking forward to submit something to next year’s EKAW and then of course to K-Cap again in two years!