CoRDI 2023
Why research data infrastructures matter - conference report

It is difficult to foster innovation and perform high quality research when the underlying data is not accessible and usable. Data and data services should be offered via so-called research data infrastructures, think of user-friendly web platforms, repositories, and databases. But how does it work in practice, and how important is the human aspect of it? I have been at the 1st Conference on Research Data Infrastructure, 12 – 14 September 2023, and got some pretty good insights. In this blog post I will reflect on the conference and cover the keynotes, the poster sessions, our own work around Knowledge Graphs and Wikibase, as well as a selection of other interesting talks.
Context
(Research) data is produced in various fields, ranging from cultural heritage and agriculture to physics and biology for example. Such data should be managed and preserved in a systematic way to accelerate scientific progress and promote collaboration, while enhancing public trust and fostering innovation.
Several large research (data) infrastructure initiatives emerged on European Level in the past decade. Those initiatives, including the European Strategy Forum on Research Infrastructures (ESFRI) or the European Open Science Cloud (EOSC), have brought hundreds of institutional partners together to build and maintain research infrastructure within numerous research projects. National initiatives have emerged as well.
Under the theme Connecting Communities, the association related to the German National Research Data Infrastructure (NFDI) organized the 1st Conference on Research Data Infrastructure (CoRDI). More than 680 persons attended this international multi-track conference which hosted 84 presentations and more than a 100 posters. Next to inspiring keynotes, there were thematic tracks at the first day and tracks related to enabling, connecting, linking, harmonizing, securing, and spreading of Research Data Management (RDM) on the remaining days.
My main takeaways
- It’s mostly about human problems that need to be fixed (connecting communities, data governance, etc)
- Knowledge Graphs and especially Wikibase gain attention in the context of research (data) infrastructures
- There is an increasing need for sustainably funded data management careers
In the rest of this post I will focus on my main highlights, not on all the presentations that I have seen. Also, since the conference was organized in the frame of NFDI, a lot of networking and promotion was devoted to the different NFDI consortia. I am not affiliated with any of these consortia and because I haven’t worked with any of those consortia in the past, this blog post is limited to my own personal (outsider) experiences at the conference. I am glad to update the post and link relevant other blog posts that provide other insides.
Table of Contents
Keynotes
Three excellent keynotes were given which gave different insights into data: Christine Borgman zoomed into the bigger picture of Knowledge Infrastructures, Julia Janssen presented how data and scientific insights can be translated into art installations, and Mark D. Wilkinson talked about his regrets when co-designing the first FAIR principles and the road ahead.
Christine Borgman – Knowledge Infrastructures
“May all your problems be technical” – Jim Gray
Christine Borgman ended her keynote (DOI: 10.5281/zenodo.8344854) with this quote from Jim Gray. And after listening to her presentation one really grasps how much truth lies in this statement. From a research data infrastructure point of view we have already a lot of platforms and initiatives. But what about data governance? To which extent do different communities agree on data management practices? According to her, we should focus on Knowledge Infrastructures, including also the social component!

One really interesting point she made is the difference between knowledge production as done by researchers and data production for others as done by data creators. Christine Borgman pledges for a data management workforce: domain data scientists, data librarians and data archivists who cover the middle ground between knowledge and data production. I fully agree! More such careers are needed (and sustainably funded) at different research institutions.
Julia Janssen – data art installations
Data, .. this anyway is something really abstract. The researcher and artist Julia Janssen has shown us in her keynote how data can be made tangible. She introduced us to some of her art installations and why and how she came up with it.

For example, according to her data from Meta (the company behind Facebook, Instagram and WhatApp), she likes the color green. She built a whole art installation with more than 4000 small balls where each ball stands for one of her interests, according to Meta. Just to try figuring out why she might like the color green. Other people literally crawled under it to get to know her better, looking at her interests trying to find out why she might like the color green.
Mark D. Wilkinson – FAIR principles
A common theme at the conference were of course the FAIR principles. The third and last keynote about those principles was given by the main author of the original FAIR principles paper, Mark D. Wilkinson (DOI: 10.5281/zenodo.8353153). Besides presenting his most recent work, he also talked about his regrets after almost 10 years since the initial version of the principles from a 2014 workshop. One of his regrets is the term data, apparently the term FAIR Digital Objects or FAIR Research Objects seems to capture their ideas better with less confusion. Also the term license turned out to be an issue, access or usage policy would have been better, avoiding the heavy legislative meaning.

But looking forward, Mark D. Wilkinson talked about (not so) autonomous agents and FAIRification in different use cases. It was nice to see that they are also using the RDF Mapping language (RML) and the YARRRML serialization format to accomplish FAIRification. Those specifications and implementations for Knowledge Graph Construction were developed by ex-colleagues of mine and I am also still using it a lot.
Poster session(s)
One of the most engaging events during a conference is of course the poster session. And CoRDI had two of it! Many, many posters and as much motivated researchers to present it. Topics covered among others anything around data management plans, terminologies, persistent identifiers, FAIR initiatives and of course posters presenting the different NFDI consortia. From the plenty of posters I will focus on two in this blog post: one more technical poster and one highlighting international collaboration.
There have been posters from various domains, and it became apparent that there is an overlap between the domains in terms of problems and solutions. For example, there was the poster from Steffen Neumann and colleagues about repository federations in the chemical domain (DOI: 10.52825/cordi.v1i.202). Among others, they work with the Open Archives Initiatives Protocol for Metadata Harvesting (OAI-PMH), which is also a common interface in the library domain where I am currently in. There I have learned that it is possible to embed JSON-LD in OAI-PMH and retrieve it via Xpath. A very handy way to publish Linked Data using already available interfaces.

Considering the Humanities domain, there was an interesting poster from Nanette Rißler-Pipka and colleagues, including my colleague Sally Chambers. (DOI: 10.52825/cordi.v1i.274). The poster focused on synergies between national and European research (data) infrastructures based on the example of the SSHOC market place. In the 8th edition of the FAIR Data Digest, I have covered with an example how differently national ERIC nodes might be linked with national initiatives (what is an ERIC? check here). Nice to see it and talk about it in real life.

MetaBelgica, Wikibase and NFDI4Culture
I participated at CoRDI to present our envisioned platform MetaBelgica which aims to become the single source of truth for cultural heritage metadata about Belgian entities of type persons, organizations, time/events and locations.
- Abstract: https://doi.org/10.52825/cordi.v1i.381
- Presentation: https://doi.org/10.5281/zenodo.8337301
For those of you subscribed to my FAIR Data Digest newsletter, you already read about the main idea behind MetaBelgica in the last edition. The following image summarizes the problem we aim to solve.
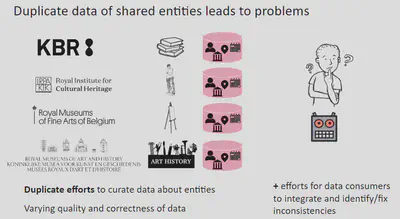
Each participating institution (left in the image) manages metadata about their own collections using domain-specific data standards. This is totally fine, because usually there aren’t any conflicts, because there is no overlap in the collections. But as part of the cataloging process, the same related data about entities such as persons or events are created by each institution separately. Over and over again. This results in duplicate efforts for the institutions and for the users.
We want to integrate the data of the partnering institutions by using the Resource Description Framework (RDF) and use the Wikibase software as a platform to manage the integrated data in a Knowledge Graph.
Knowledge Graphs at NFDI
With our submission related to Knowledge Graphs we are not alone!
Under high pressure of continuously ringing alarm bells during the national-wide sirens and (phone) alarm system test, Lozana Rossenova presented work about Knowledge Graph Infrastructure based on Wikibase (DOI: 10.52825/cordi.v1i.266). Wikibase instances are already deployed by the German National Library of Science and Technology (TIB) in the context of NFDI4Culture.
Speaking of which, Harald Sack also presented work that originated from NFDI4Culture (DOI: 10.52825/cordi.v1i.371). Their original NFDI4Culture ontology was extended to cover other NFDI consortia. In that adaptation process, the ontology was modularized into a core and several extensions.
This is great! Plenty of lessons learned and possible networking and collaboration ahead with respect to MetaBelgica.
Selection of presentations
There were tons of interesting presentations, but unfortunately I could not split myself to see all. Here is a small selection of some presentations from various domains such that you will get an idea of research data infrastructure solutions at CoRDI.
Social sciences
I have learned about the term microdata: information at the level of individual response of surveys (used in social sciences or official statistics). Dana Müller presented work about geographically separated safe rooms as part of the International Data Access Network (IDAN). In those rooms, data can be accessed without the having to leave the host institution (DOI: 10.52825/cordi.v1i.269). When looking at the following picture I am remembered of my MetaBelgica presentation, I am wondering if with respect to safe rooms there is a Belgian gap in social sciences too :-)

Data spaces
Peter Wittenburg presented the idea of FAIR Data Objects (FDOs), which according to his vision should become similarly to TCP/IP a standard protocol for data exchange (DOI: 10.52825/cordi.v1i.263). Like this, FAIR data can flow through the emerging data spaces similar to how TCP/IP packages flow through the internet.

Physics
Not my cup of tea, but apparently there are a lot of physical sciences data infrastructures in the UK. And as we have learned further in the presentation given by Nicola Knight, there are also alignments with the NFDI (DOI: 10.52825/cordi.v1i.339).

Scholarly Communication
Even though we have all the open and FAIR data and code repositories, the actual way of scholarly communication via research papers has not change much over the centuries. Sören Auer presented the Open Research Knowledge Graph (ORKG) and how they plan to change that (DOI: 10.52825/cordi.v1i.272). One adds structured information about the contributions of a specific paper to the Knowledge Graph via a web interface. Comparisons and visualizations can be created on the fly, everything gets DOIs and is thus citable. They also experimented already to promote the ORKG earlier in the publication process, for example as preparation for the submission to the SEMANTiCS conference according to Sören Auer.

Research Data Management
A whole team of people presented the state initiatives for Research Data Management (DOI: 10.52825/cordi.v1i.242). The following image shows some German states that are already participating in this initiative. They do some necessary field-work, providing support to researchers directly, or support smaller members such as Universities of Applied Sciences in grant applications.

Networking
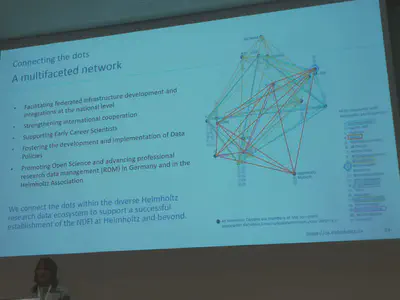
Last but not least, Nina Leonie Weisweiler presented the engagement of the Helmholtz association in NFDI (DOI: 10.52825/cordi.v1i.402). The following image nicely shows which Helmholtz centre is active in which NFDI consortium. Internally, the different NFDI representatives of Helmholtz regularly sit together to discuss their involvement, great initiative!
Final remarks
This is it, I hope you enjoyed reading this blog post about CoRDI 2023. Let me know if you have any questions, feedback or remarks.
Thanks to the whole CoRDI team for making this edition happen! I am looking forward to a possible 2025 edition of CoRDI to learn about the progress of the community.
In the meantime, there will be another NFDI event in 2024, but apparently slightly smaller, because the combined NFDI and EOSC communities are too big for a suitable venue.

Don’t forget to share this post on social media and in your networks! Please also consider subscribing to my bi-weekly Newsletter FAIR Data Digest to receive more interesting content every other Tuesday!