
The European Economic Area is one of the best use cases for (semantic) data integration: the many different languages, legislations, rules and systems must be or become interoperable! On October 8 and 9, 2025, I attended the 3rd European Data Conference on Reference Data and Semantics (ENDORSE) in the European Commission’s building Charlemagne in Brussels, Belgium. In this blog post I will reflect on the conference, provide details from some of the presentations, and talk about my own presentation in the Cultural Heritage session.
Context
Several hundred people participated in this year’s ENDORSE conference in person and many watched the sessions via an online livestream. A total of 85 speakers participated in 45 accepted presentations (out of 61 submissions), 8 posters, 2 panels and 3 keynotes.
The Publications Office of the European Union, which organized the conference already highlighted several key messages in a LinkedIn post.
(1) Data, semantics and AI must work hand in hand to build services that are truly citizen- and business-centric.
(2) The power of AI depends on the quality, precision and multilingual nature of the data it learns from, a uniquely European strength.
(3) Semantic interoperability used to be a niche field. Today it’s a strategic enabler of Europe’s digital transformation.
(4) Collaboration, co-creation and trust remain the foundations of an interoperable and inclusive digital ecosystem.
(5) Execution matters! Turning insights and knowledge into concrete actions is how we deliver meaningful impact.
(6) A key takeaway? Reference data is the glue that binds all these areas, a message that resonated strongly throughout our vibrant networking sessions.
I can only agree! This conference was a great networking event for the GovTech sector where Semantic Web standards and technologies are put into practice.
I keep this post short and only focus on my own takeaways, a few details from some of the presentations and my own contribution related to the use of Wikibase in the MetaBelgica project.
My main takeaways
-
From vocabularies to application profiles: governance matters
-
Linked Data meets Generative AI meets data spaces: existing structured knowledge can be offered via the MCP protocol to generative AI models, but also well-documented specifications make it more human and machine-friendly
-
The professional conference setup really made a difference: professional moderators, time keepers and online streaming all made the conference visit a nice experience
One downside of the conference: the speaker’s presentations, one of the main outcomes of the conference, are only available via links on the ENDORSE website and hence are not FAIR. I would have loved to cite all the presentations that I mention with a DOI. Providing all presentations via e.g. a Zenodo community (like done for the CoRDI conference) would have been a great solution to make the outcome of ENDORSE FAIR.
Data stewardship in the Age of AI
In his keynote about the future of data stewardship, Stefaan Verhulst from the Govlab covered many interesting topics around what he called the emergence of open data winter while having an AI summer.
According to Stefaan we witness the emergence of an open data winter: access to data is backsliding, so is the excitement for open gov data and even Creative Commons sees a decline in licensing. A general GenAI anxiety is noticeable, yet there is hope: we are able to ride the fourth wave of Open Data.
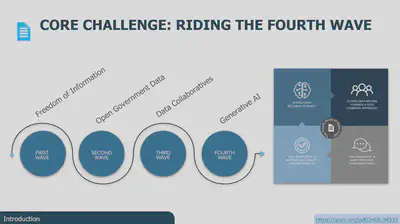
In a nutshell, this inspiring keynote introduced the following six shifts in data stewardship, to become more strategic and prevent an open data winter.
- supply => demand (become demand-centric, key questions regarding a problem and need for evidence for decision makers)
- datasets => Knowledge Graphs for interoperability
- structured data => unstructured data (Large Language Models like unstructured data, but it was never part of data management)
- consent => social license (to engage with communities, current consent is flawed in multiple ways)
- FAIR => FAIR-R (AI-ready, authoritative provenance, model context protocol (connection from AI to external systems))
- Open Data => data commons (GenAI anxiety, common-crawl + wikipedia fuels model training to a large extent, following the theories of Elenor Ostrom: govern resources in ways that are not extractive and align with principles and expectations of those that created the data or make it accessible, data commons prices)
Stefaan’s talk looked into problems at the horizon and how we could deal with them. Data governance and openness are not static goals but evolving practices. The next presentations showed how these principles are already being applied in concrete public sector contexts.
Interoperable Public Services and Data Spaces
In her keynote, Kjersti Steien from the Norwegian Digitalisation Agency (Digdir) talked about the implementation of Public Services in Norway.
Similar to other European countries, Norway also have a catalog of public services. Even though Norway is not a member of the EU, they use the Core Public Service Vocabulary Application Profile (CPSV-AP) of the EU.
More specifically, their service catalog is described in the Norwegian extension CPSV-AP-NO and can also be connected to relevant concepts described with SKOS-AP-NO, and datasets according to the DCAT-AP-NO model. A nice detail: the Norwegian CPSV extension also includes services delivered by the private sector.
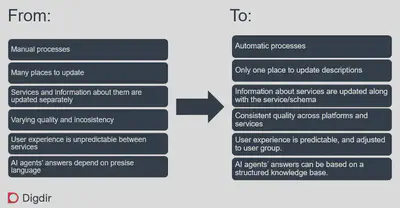
This example shows how EU application profiles can provide a shared basis even beyond EU borders. At the same time, national approaches still vary quite a lot.
During the conference I have learned, that also Germany has a catalog of public services: the FIM portal (presentation by Felicitats Löffler and Marianne Mauch from the state of Thuringia, the green heart of Germany). However, it is not derived from CPSV-AP and I don’t think it is mapped to it yet. This brings me to an interesting point mentioned by Kjersti:
It would be great if the EU would recommend CPSV-AP as one of the specifications to use with the Single Digital Gateway
These different implementations underline that even with good standards, alignment still depends on manual curation and coordination between actors.
Overall the work on public service descriptions makes me think of two things: first, how important manual data curation is. Secondly, on some work I did a few years ago in the FAST project, on providing personalized workflows for life events to improve the customer journey (presentation)
After several talks on interoperability across administrations, the next keynote (which was the first of the conference actually) focused on Knowledge systems in general and what it means to make data understandable for both humans and machines.
Provenance and Agreement
In his keynote, Paul Groth from VU Amsterdam (co-author of the W3C PROV standard and the FAIR data principles) covered several topics related to Knowledge Engineering and Large Language Models (LLMs).
One interesting thing that I’ve learned about in Paul’s talk is C2PA, a global standard for content authenticity, that recently was integrated into Android. Basically it adds Content Credentials via cryptographical methods to digital media and thus the necessary provenance to verify that a certain image or video was created and not generated by AI. Something similar I’ve seen at the poster of the Piveau-X catalog, uploaded content needs to be cryptographically verified.

Paul also talked about how important, but also how time consuming, it is to work on standards and find agreement. He gave the example of the W3C PROV specification, where he and others were involved in in 8820 public E-mails, 666 issues, 600 Wiki pages, 6000 mercurial commits and 152 teleconferences.
What I take home from this talk:
Make standards more human readable, so they are more machine (LLM) readable
Adding more documentation to your specifications and data models is never a bad idea :-)
Paul’s talk highlighted the effort that goes into developing common standards and the importance of documenting them well. The following presentation by Bert Van Nuffelen from Digitaal Vlaanderen gave a concrete example about Knowledge Engineering of the Open Standards for Linked Organizations (OSLO) in Flanders, Belgium.
He highlighted the fact that reuse of knowledge is important, but also that it can lead to questions regarding data governance. For example, certain constraints should not be defined directly on the concepts in the namespace of a vocabulary, but rather in the application profile that reuses terms of this vocabulary.
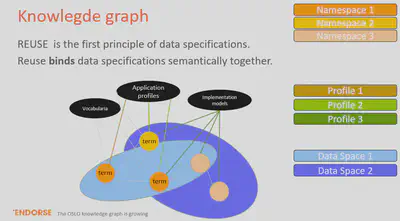
However, how does the governance of an application profile actually works in practice? After all, the reused terms are governed in vocabularies of different namespaces. The emergence of data spaces aggravates the situation, because several data spaces can make use of a mix of different application profiles and vocabulary terms.
The OSLO presentation did not stop at data governance. It also touched on how AI systems can interact directly with these well-defined semantics.
OSLO allows language models to query its structured descriptions through a Model Context Protocol (MCP) server, which is an interesting step towards connecting Linked Data with generative AI. I first learned about MCP at this conference. While Paul Groth advocated for more machine-readable standards, the MCP approach demonstrates how machines can use them in practice.
Talking about data spaces, they were another recurring topic at this year’s ENDORSE. In one of the panels it was said that, in theory, you could even run a data space on paper. This highlights how much the concept still depends on governance rather than technology. So far there is not one single standard, but several coexisting initiatives and implementations.
During the discussion, moderated by Pieter Colpaert, one speaker mentioned the browser wars of the 1990s: many competing implementations, not all interoperable yet. The International Data Spaces Association (IDSA) was mentioned as one of the key players, and the European Commission already recognizes more than 70 common European data spaces even if it is not always clear to me what qualifies as one.
What I found particularly interesting was the perspective on procurement. Instead of one large platform where only big companies can compete, data spaces could allow smaller providers to offer interoperable services. The sovereignty of participants and the absence of monopolies were highlighted as essential principles. The main recommendation from the panel: don’t make the definition of a data space too strict, it’s better to have working examples than theoretical perfection.
These discussions about interoperability, governance and shared infrastructures also resonated strongly in the cultural heritage session, where I presented our own approach to data management in the MetaBelgica project.
MetaBelgica: central vs decentralized data management
This year’s ENDORSE also featured a session on cultural heritage. Besides presentations about DE-BIAS from Orfeas Menis Mastromichalakis, the Dutch data space for cultural heritage from Enno Meijers and a case study for historical encyclopedias from Thora Hagen, I presented work of our MetaBelgica project.
In particular, my presentation focused about our choices on data management. On the one hand, due to existing legacy systems and duplicate efforts in data curation, we opted to not have a fully decentralized solution.
On the other hand, we also did not choose a fully centralized solution, to avoid having a single-point of failure system in which partners from several institutions have to maintain all their data.
Instead we have chosen for a Wikibase system that I situate in-between with a best-of-both worlds approach: Loosely coupled FAIR data.
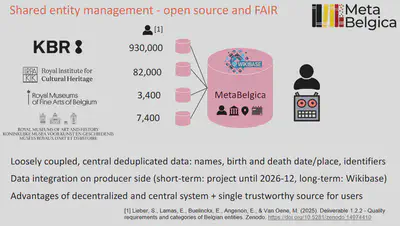
We rely on the mature data management software Wikibase (with Technology Readiness Level 9), while keeping a balance of control and collaboration. For example, we keep local autonomy and possible additional institution-specific data, while providing de-duplicated high quality FAIR reference data in a single trustworthy system with Persistent Identifiers for the public.
Final remarks
ENDORSE 2025 once again showed how Europe combines technical precision with collaboration. From open data stewardship and interoperable public services to AI-ready standards, the conference made clear that the future of digital government depends on connecting structured knowledge and the people maintaining it. This post only covered a few talks that I found particularly interesting, there are many more presentations (and recordings) to be discovered on the ENDORSE website.
References
- Lieber, S. (2019, June 25). The FAST project: Criterion and Evidence from the Public Service UX perspective. Zenodo. https://doi.org/10.5281/zenodo.8001639
- Lieber, S. (2025, October 8). Opening up Belgian Cultural Heritage Reference Data with Wikibase. The European Data Conference on Reference Data And Semantics (ENDORSE), Brussels, Belgium. Zenodo. https://doi.org/10.5281/zenodo.17344191