
Did you ever use a language learning app and were annoyed that the exercises are either too easy or too hard? That are actually reasons people give up. Well, probably you would profit from adaptive learning systems, which adapt the difficulty of the exercises to your abilities! Providing Adaptive Learning Analytics Systems with data to do that, is one part of a project I am currently working on.
This paper which was accepted at the Linked Learning (LILE) workshop at the WebScience2018 conference describes how we generate Linked Data out of learning activity data (logfiles generated when you are using an educational app). Learn here what Linked Data is, how it can help and how we also use something called Provenance to assist the users of our system with data protection tasks.
Problem
Adapting exercise difficulties to your abilities is possible using e.g. Machine Learning algorithms. These algorithms need to be trained and therefore need looooots of data! But not just any data, the bare nature of an exercise needs to be described (is this an grammatical task? audio task?), also YOU and users in general need to be described (do you have learning disabilities like dyslexia? what do you already know?) and of course these data then needs to be integrated. Strictly speaking, the machine needs to understand that a certain concept like a disability relates somehow to certain other concepts like grammar (which is then an essential part of an exercise).
Solution
Describe exercises and users with the help of semantic technologies and doing that as additional step on already existing learning data.
How do we describe things semantically so machines can understand it? Therefore we are using Linked Data! Basically Linked Data is a set of design principles. Every concept you describe,
- should have an unique identifier (you say what a Person is and give it the unique name Person)
- needs to be dereferenceable (a machine using your concept of a Person should be able to look up what it means) => http://xmlns.com/foaf/spec/#term_Person would be unique and as it is a web resource also dereferenceable
- should be described using standards (define your concept of a person using a standard like RDF ensures that a machine can read it)
- should re-use and link to other concepts already existing.
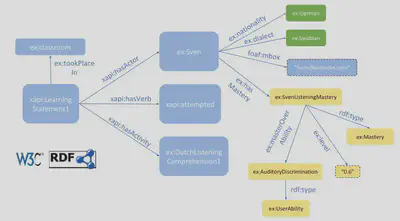
In that picture you see an example of Linked Data, expressed as a graph. Different colors indicate the different domains the data comes from. The data describing your performed learning activities (blue), data about you (and users in general) (green) and data regarding your abilities (yellow), the prefixes are shortcuts for an URI.
And there you see that we already successful integrated data from these different domains!
That looks like a nice solution, right? But how do we get the Linked Data?
We are not forcing anyone to change now the way they collect learning activity data. The only thing we require are learning activity data according to the xAPI specification. That is a structured text format, which is already used a lot. The learning activity data are usually stored in special databases called Learning Record Stores. Our solution works on top of that, meaning, we extract the data out of these databases.
Actually we built a small pipeline, which uses standard technologies like JSON-LD to lift the structured text data to actual Linked Data resources!
For each step in the pipeline, we also collect Provenance information which we make available as Linked Data as well. Why that you may ask?! Well, current privacy law like the European General Data Protection Regulation (GDPR) grant persons whose private data are processed certain rights. They (or in that case you as well) can request to delete or correct data which is about you. If such a request was made, the users of our application can query the generated Linked Data and based on the provenance information they see where the data comes from and when it was extracted, which enables then to delete or correct the personal data everywhere.