
Auch schon mal geärgert das Übungen einer Sprachlern-App entweder zu schwer oder zu einfach sind? Tatsächlich sind das Gründe, weshalb viele Leute aufgeben. Vermutlich würde es den Nutzern einer solchen Sprachlern-App nützen, wenn ein adaptives Lernanalysesystem verwendet wird, welches sich auf die Fähigkeiten der Nutzer einstellt. Das Bereitstellen eines adaptiven Lernanalysesystems samt Daten, ist Teil eines Projekts an dem ich momentan arbeite.
Dieses Paper wurde beim Linked Learning (LILE) workshop bei der WebScience2018 Konferenz angenommen, und beschreibt wie aus Lernaktivitätsdaten (Logfiles welche generiert werden während eine pädagogische App verwendet wird) Linked Data generiert werden kann. Im folgenden wird beschrieben was Linked Data ist, wie es beim adaptiven Lernen helfen kann und wie wir etwas namens Provenance benutzen um Benutzern unseres Systems bei Datenschutzaufgaben behilflich zu sein.
Problem
Das Anpassen vom Schwierigkeitsgrad einer Aufgabe, basierend auf Fähgikeiten des Nutzers, kann durch maschinelles Lernen ermöglicht werden. Maschinenlernalgorithmen müssen trainiert werden und benötigen eine Menge Daten! Die Art der Aufgabe muss beschrieben werden (ist es eine grammatikalische Aufgabe? audiovisuell?), aber auch Daten bezüglich der Nutzer (sind Lernschwächen wie Dyslexie bekannt? Was weis ein Nutzer bereits?). All diese Daten müssen dann natürlich noch integriert werden um verwendbar zu sein. Anders ausgedrückt: Ein Programm muss verstehen das ein bestimmtes Konzept wie eine Lernschwäche in Beziehung zu anderen Konzepten wie Grammatik steht (welches dann ein wesentlicher Teil einer Aufgabe ist).
Lösung
Das Beschreiben von Aufgaben und Nutzern mit der Hilfe von semantischen Technologien, als zusätzlichen Verarbeitungsschritt von existierenden Lernaktivitätsdaten.
Wie können wir Dinge semantisch beschreiben damit auch Programme es verstehen können? Dafür verwenden wir Linked Data! Im Grunde ist Linked Data eine Menge von Design-Prinzipien, jedes beschriebene Konzept
- sollte eine eindeutige Kennzeichnung besitzen (Man beschreibt bspw. ein Konzept und gibt ihm den Namen “Person”)
- sollte dereferenzierbar sein (Ein Programm welches unser “Person” Konzept verwendet, muss in der Lage sein nachzusehen was eine Person ist) => http://xmlns.com/foaf/spec/#term_Person ist eine eindeutige Kennzeichnung da eine URL verwendet wird, und daher ebenfalls dereferenzierbar für ein Programm
- sollte mit Standards beschrieben werden (Die Definition eines Konzepts “Person” mittels eines Standards wie RDF stellt sicher das ein Programm es verarbeiten kann)
- sollte wiederverwendbar sein und zu anderen existierenden Konzepten verlinken.
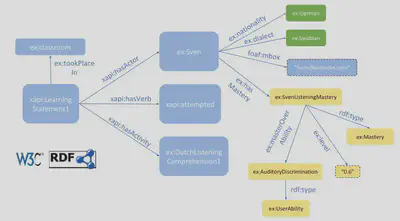
Das Bild zeigt ein Linked Data Beispiel als Graph. Verschiedene Farben repräsentieren verschiedene Domänen. Daten welche Lernaktivitäten beschreiben sind blau dargestellt, Daten welche Nutzer beschreiben grün, und Daten welche Fähigkeiten beschreiben (gelb). Die Präfixe sind Abkürzungen für eine URI.
Und siehe da, wir haben die Daten von verschiedenen Domänen bereits in einem einheitlichen Graphmodell integriert! Das sieht nach einer schönen Lösung aus, richtig? Aber wie bekommen wir Linked Data?
Wir zwingen niemanden die Art und Weise wie Lernaktivitätsdaten generiert werden zu ändern. Die Einzige Voraussetzung die wir haben ist, dass Lernaktivitätsdaten mittels der xAPI Spezifikation beschrieben werden. XAPI ist ein strukturiertes Textformat, welches bereits breite Anwendung findet. Lernaktivitätsdaten sind für gewöhnlich in speziellen Datenbanken, genannt Learning Record Stores, gespeichert. Unsere Lösung baut auf diesen Learning Record Stores auf, in anderen Worten: Wir extrahieren Daten aus diesen Datenbanken.
Wir konstruierten eine Pipeline, welche Standardtechnologien wie JSON-LD verwendet, um die strukturierten Textdaten zu Linked Data zu transformieren.
Für jeden Verarbeitungsschritt in der Pipeline sammeln wir auch Provenance Informationen, welche wir ebenfalls mithilfe von Linked Data beschreiben. Warum das? Nunja, geltendes Datenschutzrecht wie die Datenschutzgrundverordung (DSGVO, engl. GDPR) gewährt Personen deren persönliche Daten verarbeitet werden verschiedene Rechte. Personen können beantragen das ihre Daten gelöscht, oder korrigiert werden. Falls solch ein Antrag eingeht, können Benutzer unserer Applikation basierend auf bestehenden Linked Data Provenance Informationen abfragen woher Lernaktivitätsdaten kommen und wann sie extrahiert worden sind. Das ermöglicht die Löschung oder Korrektur personenbezogener Daten in der Quelle und ggf. allen Kopien die durch Verarbeitungsschritte erzeugt wurden.