RDF named graphs
A powerful data management technique to provide context, but what is it and how can it be used with the query language SPARQL?
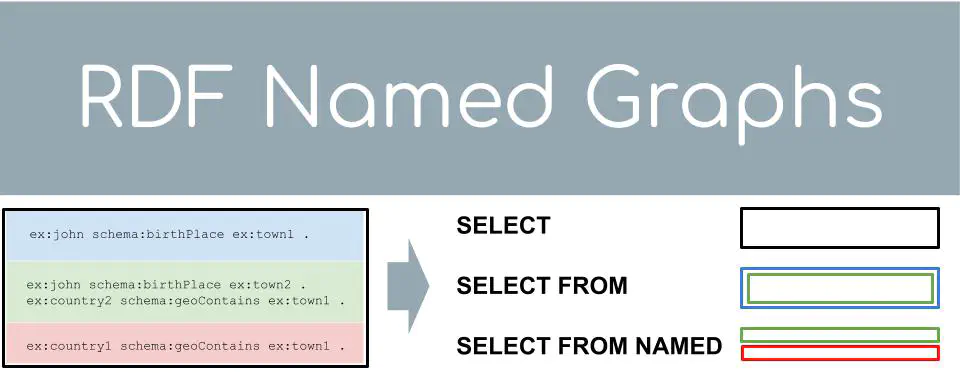
With the Resource Description Framework (RDF) you can represent Linked Data as subject-predicate-object triples. But what if you have to represent additional context of those triples? In this Blog post I will briefly introduce the advanced data management feature “named graphs” with two examples: different data source named graphs in the BELTRANS project and different story-contexts for Digital Humanities research. Furthermore I will graphically illustrate the different ways you can query named graphs with SPARQL!
Context
Linked Data represented using the Resource Description Framework (RDF) consists of subject, predicate and object triples! This is what you will learn in any introduction to Linked Data.
However, did you know that with RDF you can also have Quads? Statements with four components: subject, predicate, object and context. Continue reading for some practical examples and graphical illustrations.
Example of named graphs for provenance information
According to the Data Management chapter of the Linked Data Patterns website, named graphs can be used for different purposes such as expressing the provenance of triples, use the named graph for access control, or in general for data management.
In the BELTRANS project where we collect data from various sources, we store the data of each data source in a separated named graph. One the one hand, this allows us to update a specific data source independent of other data sources, and on the other hand, we can refer to a triple by its data source as the following example illustrates.
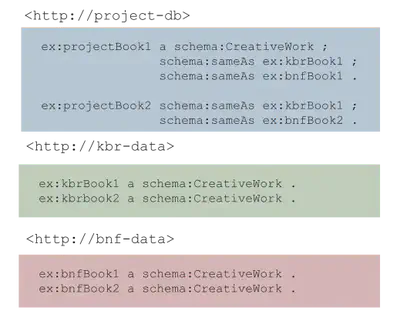
We have a named graph containing RDF triples that describe book translations in our project database (<http://project-db>).
Each of this book descriptions might be available in data
that we obtained from different national libraries (our data sources <http://kbr-data> and <http://bnf-data>).
This is represented by having a schema:sameAs link from the book description
in the project named graph to the different data source named graphs.
Without named graphs, the generic schema:sameAs link would not allow us
to distinguish the descriptions of the book in one particular data source by using SPARQL.
A side note: it might be possible by using a FILTER expression on the string representation of the URI.
For example, if URI starts with http://data.bnf.fr it probably is a book from the National Library of France.
However, this is a bit against the idea of the Semantic Web,
because now we assume semantics based on the name of the thing and not via explicitly expressed semantics with RDF terms. This is considered a bad practice.
With named graphs, however, we have a way to semantically express the context of a book description using explicit RDF statements. In a SPARQL query we could do the following if named graphs are used for data of each data source:
SELECT ?bookURI ?kbrURI ?bnfURI
WHERE {
# we are interested in book descriptions from our project database
graph <http://project-db> { ?bookURI a schema:CreativeWork . }
# based on the named graph context, identify the KBR book description
OPTIONAL {
graph <http://project-db> { ?bookURI schema:sameAs ?kbrURI . }
graph <http://kbr-data> { ?kbrURI a schema:CreativeWork . }
}
# based on the named graph context, identify the BnF book description
OPTIONAL {
graph <http://project-db> { ?bookURI schema:sameAs ?bnfURI . }
graph <http://bnf-data> { ?bnfURI a schema:CreativeWork . }
}
}
In this example, the specific URI linked via schema:sameAs
also has to be a book description in a specific named graph.
Like this, we can distinguish in the SPARQL query based on the named graph context,
in which schema:sameAs we are interested in.
Illustrations of different ways to query named graph data
You have already seen that I have used the graph keyword in the SPARQL query above.
But there are more possibilities!
To illustrate these possibilities, namely the keywords FROM and FROM NAMED, I will consider a slightly different example,
inspired from a presentation at the DHBenelux conference 2023
about Greek Mythology.
In the following example, we are interested in the fictional character john and his place of birth according to different novels.
Each novel is represented as a different named graph, i.e. <http://story-1>, <http://story-2>, and <http://story-3>.

Somewhere in the first novel, it is mentioned that john was born in ex:town1.
The second novel even specifies that ex:town1 is located in country ex:country2.
However, the second novel does also state that john was born in ex:town2.
Last but not least,
according to the third novel, the city ex:town1 is in country ex:country1.
This example should illustrate that each novel provides its own context.
The john of novel 1 might not be the same of the john in novel 2.
Similarly, one could say that ex:town1 is the same as ex:town2
or that ex:country1 is the same as ex:country2.
But, are these entities actually the same?
This might be a complex and even philosophical discussion.
Instead of explicitly indicating that something is the same as something else,
we can simply keep the context of each story.
What we know is that ex:john appears in all three novels.
Let’s assume, that the fact that john is a (fictional) Person (e.g. by indicating a schema:Person) is specified without any specific context (named graph).
The tricky part is now how to query the data.
Depending on your use case you have different options which are visualized below.
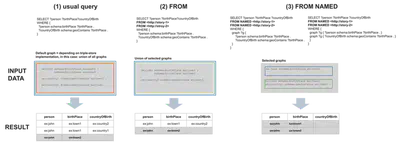
In the illustration we see that each query returns different results.
Let’s have a look what each of the queries does.
One remark: The values in the output that are strikethrough will not be part of the result,
because not every variable of the triple pattern will be bound.
If you would wrap the triple pattern to fetch the country into an OPTIONAL,
you would get those results too.
(1) In the first case no graph is explicitly specified. Thus the default graph will be queried.
Depending on the triple store (RDF database) you are using,
the default graph might be yet another named graph which in our example is almost empty.
Remember, it only contains the triple that ex:john is a person.
However, in this example we assume that the default graph
is a union of all named graphs: an inclusive strategy.
(2) In the second case, we explicitly specify with the FROM clause,
which named graphs the query should consider.
If you do not specify any context in the triple patterns of the query,
the query looks into the union of the specified named graphs.
As expected, data of <http://story-3> is not queried and will thus not be part of the output.
(3) In the third case, we similarly specify named graphs explicitly,
this case with the FROM NAMED clause.
Like this the query loops over each of the mentioned named graphs.
This means, that when producing one result set (one row of the output),
the variable for the named graph is bound to only one named graph.
Therefore it is not possible to query across named graphs.
And this is exactly why for the given data,
no results will be provided.
As you can see, a named graph is also just a URI! Therefore we can use properties to describe the context as well. For example
<http://story-1> a schema:Book ;
schema:about ex:john ;
schema:author ex:author .
And where you store this information is up to you. Now you know how you can retrieve it with SPARQL!
Final remarks
Named graphs can be a powerful data management technique. Yet you have to be aware of different implementations, especially if you change your software stack at some point. Additionally, it makes SPARQL queries slightly more complex which may look scary for beginners.
Besides the RDF and SPARQL specifications, you can find more information about named graphs at this Blog post from the company metaphacts, or at this Blog post from the company Stardog.
Curious about more content like this or some behind-the-scenes? Consider subscribing to my bi-weekly Newsletter FAIR Data Digest to receive more interesting content about Linked Data every other Tuesday!